
C# 식별자와 키워드
목차
식별자는 간단히 말하면 타입의 이름입니다. 변수의 이름, 클래스의 이름, 메소드의 이름 등등 사용자가 이름을 짓는 것은 모두 식별자입니다. 기술적으로는 소스코드에서 타입을 나타내는 문자열이라고 말할 수 있습니다.
그냥 이름이라고 하는데 왜 식별자(Identifier)라고 하냐면 어떤 데이터를 다룰 때 식별이 가능해야 하기 때문입니다. 예를 들어서 a와 b라는 변수가 있습니다. a는 사실은 그 값이 저장된 메모리의 주소와 매핑되어 있습니다. a라는 이름에 두개의 변수를 연결시킬 수는 없기 때문에 a, b 이렇게 식별이 가능하도록 해야 합니다. 너무나 당연한 설명이지만 이제 두가지 측면에서 살펴보면 의미가 있습니다.
첫번째는 컴파일러의 관점입니다. 프로그래머가 작성하는 소스코드 상에는 나타나 있지 않지만 컴파일러가 작업을 할 때는 다양한 식별자들이 추가 됩니다. 예를 들어서 System 네임스페이스에 있는 BCL(Base Class Library)에 수많은 식별자가 들어 있습니다. 또 컴파일러가 보유한 키워드들이 있는데 만일 사용자가 중복된 식별자를 변수의 이름으로 사용하면 컴파일러는 어느 한쪽을 사용할 수 밖에 없습니다. 이런 충돌 문제를 해결하기 위해서 C# 컴파일러는 규칙을 정해놓았습니다. 식별자에 대해서는 C# 뿐만 아니라 다른 언어들도 몇가지 차이점은 있지만 거의 비슷한 규칙이 있습니다.
두번째는 소스 코드를 작성하고 유지 보수하는 사용자의 관점입니다. 컴파일러의 규칙만 잘 지킨다면 어떤 식별자를 사용하건 프로그램은 잘 돌아갑니다. 극단적으로는 10개의 클래스를 사용하는 네트워크 프로그램이 있는데 클래스의 이름을 a1, a2, a3 … a10 이렇게 지어도 문제없이 동작합니다. 하지만 코드에 문제가 생겼을 때 혹은 업데이트를 해야할 때 이 코드를 유지보수하는데는 상당한 어려움이 있을 것 입니다. 작성자가 아니라 다른 사람이 코드를 이어받았다면 더욱 해석이 불가능할 것 입니다. 그래서 a1, a2… 이렇게 만들지 않고 ClientInstance, ServerInstance 처럼 의미를 부여하는 것 입니다. 코드의 가독성, 즉 얼마나 쉽게 읽을 수 있는가는 생산성과 연결되므로 결국 식별자를 만들때는 최대한 돈값을 하는 이름을 만들어야 합니다.
이름은 무한대로 지을 수 있으니까 때로는 막연합니다. 또 사람들은 대부분 비슷한 생각을 하기 때문에 여러 사람이 함께 일하는 환경에서는 다른 사람의 식별자와 충돌하는지 않게 주의해야 합니다.
실제로 프로그래머에 따라서 식별자를 짓는데 시간을 많이 들이기도 합니다. 너무 어려운 이름을 사용하는 것보다 이 소스코드를 처음보더라도 의미를 파악해서 바로 사용할 수 있도록 하는게 포인트입니다. 어렵게 생각하면 어렵지만 상식적으로 프레임워크의 구조에 맞춰서 이름을 지으면 됩니다. 예를 들어서 시험 점수라면 examScore 학생 클래스의 필드라고 하면…
Student Mike = new Student("Mike");
Mike.examScore = 85;뭐 이런식의 코드는 이해하기가 쉽습니다. Mike 라는 학생의 examScore 라고 알 수 있습니다. (클래스의 문법을 아직 배우지 않아도 영어 단어만 읽어도 대충 뜻이 짐작 가능할 것 입니다) 같은 코드를 아래와 같이 철자로 축약해서 작성해봅니다. 딱 봐도 무슨말인지 이해가 어렵습니다. St를 보고 보통은 student 가 생각이 날 것 같지 않습니다. 이러한 식별자가 수십개만 늘어나도 해석불능입니다. 코드는 실행되겠으나 유지보수는 상당히 고난입니다.
St s1 = new St("Mike");
Mike.sc = 85;식별자 규칙
식별자 규칙은 컴파일러의 규칙입니다. 사람에게 가독성이 나쁜 코드도 컴파일만 되면 잘 돌아가지만 식별자의 규칙을 지키지 않으면 컴파일 에러가 납니다. 이것은 언어를 개발할 때 규칙을 정한 것 입니다.
- 영문 알파벳과 언더스코어 _ 를 사용할 수 있습니다. (a~z, A~Z, _)
– 사실 UTF-8 인코딩을 사용하는 현대의 컴파일러는 한글도 사용할 수 있습니다만, 아무래도 권장되지는 않습니다. 영어로만 코딩한다는 일종의 편견일 수도 있는데 현업에서 사용하기엔 무리가 있겠습니다. (개인 토이 프로젝트라면 말리지는 않음) - 영문 대문자와 소문자를 구분합니다.
– 이것을 case-sensitive 라고 합니다. A와 a는 다른 문자입니다. 아스키코드가 다르니까 컴파일러에게는 다른 문자입니다. - 숫자는 첫번째에 나올 수 없습니다.
– 예를 들어 2myAge 이건 안되고 myAge2 이건 됩니다. 숫자를 첫번째에 넣지 않는 것은 다른 언어의 컴파일러도 대부분 가진 규칙인데 소스코드의 숫자(아스키 코드)에는 리터럴 상수를 우선적으로 할당하는게 효율적이기 때문으로 보입니다. 또 가독성 측면에도 좋지 않겠지요. - @는 식별자의 첫번째 문자로 사용가능합니다. 다른 위치에서는 허용되지 않습니다.
– @의 사용은 권장되지 않습니다.
네이밍 컨벤션(naming convention)
네이밍 컨벤션은 작명 방식 정도로 번역할 수 있습니다만, 대규모 프로그램을 개발할 때 팀원간에 지켜야 하는 규칙입니다. 컴파일러의 식별자 규칙이 기계적인 규칙이면 이쪽은 사람간의 의미전달에 포커스가 있습니다. 소속이 없이 혼자 프로그래밍을 하더라도 오픈소스 프로젝트 소스 코드는 그 커뮤니티의 네이밍 컨벤션을 따릅니다. 또 대기업들 같은 경우 네이밍 컨벤션이 표준화 되어 있습니다. 예를 들어서 구글의 스타일을 알고 싶다면 구글 검색에서 “google naming convention”을 검색하면 많은 문서가 나옵니다. 파일 이름 부터 변수이름 짓는 것 까지 온갖 내용들이 정리되어 있습니다.
이름을 어떻게 지어야 할지 모르겠다면 BCL(Base Class Library)을 참고하도록 합니다. 결국은 좋은 소스코드를 많이 읽고 실습 프로젝트를 통해 내 것으로 소화하는 방법밖에 없습니다. (회사라면 팀의 네이밍 컨벤션을 따라하면 됩니다)
키워드(keyword)
키워드(keyword)는 C# 컴파일러가 특별한 의미를 정의한 문자열입니다. 아래 C#의 키워드는 식별자로 사용할 수 없습니다. 키워드 앞에 @를 붙이면 식별자로 사용할 수 있긴 하지만 적절하지 않습니다.
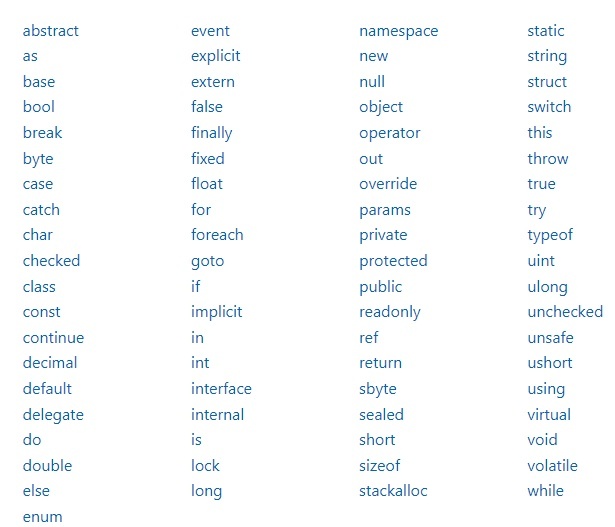
상황별 키워드는 특정한 상황에서(Contextual) 키워드로 의미를 갖고 그 외의 영역에서는 식별자로 사용할 수 있습니다. 그렇다고 해도 권장되지 않습니다. 마이크로 소프트의 문서에 따르면 C#에 새로운 키워드가 업데이트 될 때 이전 버전과의 호환성을 위해 상황별 키워드로 추가된다고 합니다.

키워드는 대부분 C# 문법을 구성합니다. 여기에 나온 키워드를 거의 다 사용할 수 있을 때 쯤 이면 C# 기초과정이 끝날 것 입니다.
요약
C# 식별자와 키워드에 대해서 알아봤습니다. 식별자에는 규칙이 있는데 컴파일러에 지켜야할 규칙과 커뮤니티에서 지켜야 할 네이밍 컨벤션으로 나눌 수 있습니다. 키워드는 C# 이 특별한 의미로 사용하는 토큰입니다. 중요한 것은 키워드를 식별자로 사용하지 말아야 합니다.
참고문서
https://docs.microsoft.com/ko-kr/dotnet/csharp/language-reference/keywords/