
배열(Arrays)
목차
C언어의 배열은 기본이 되는 자료구조입니다.
배열은 같은 타입의 데이터를 순서대로 저장하는 방식으로 메모리를 사용하는 가장 원초적인 방법으로 볼 수 있습니다.
C언어 기본과정을 학습할 때 배열에 대한 학습을 하지만 자료구조 학습을 위해서는 그보다 더 상세한 학습이 필요합니다. C의 기초과정에서는 그렇게 까지 심화해서 내용을 보지는 않지만 자료구조에서는 배열의 모든 것을 이해하기 위한 내용이 담겨 있습니다. 꼭 프로그래머가 아니라 향후 컴퓨터 관련 일을 할 때에 큰 힘이 될 수 있는 지식입니다.
배열(Arrays)이 가끔 변수(Variable)와 비교되기도 하는데 변수는 데이터 타입을 가지고 수정이 가능한 메모리 공간이고, 변수의 이름은 메모리에 붙인 일종의 이름표(Label)입니다.
배열은 같은 타입의 변수를 묶어서 사용하는 것 입니다. 같은 데이터 타입의 변수를 대량으로 사용해야할 때 진가가 발휘됩니다.
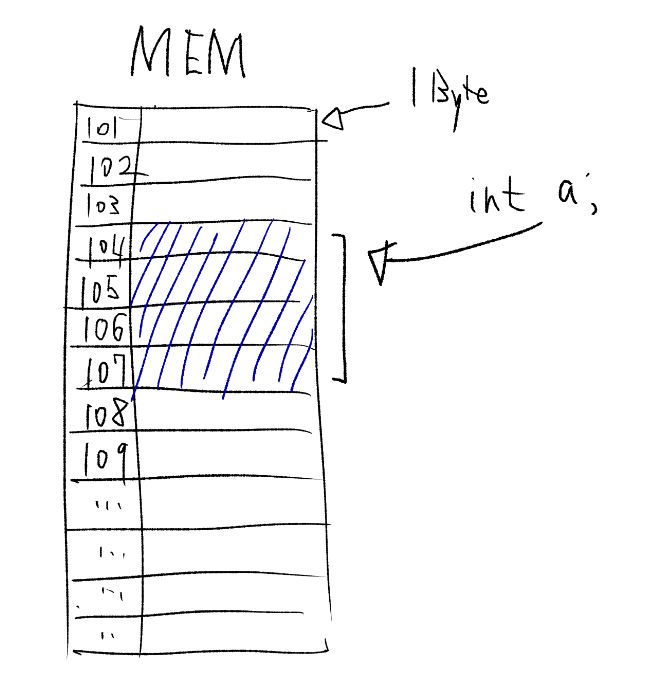
원리적인 부분을 살펴보면 우리가 데이터를 사용하기 위해서는 메모리에 저장해야 합니다. 메모리는 주소가 있고 예를 들어 32비트의 메모리는 0x0000 0000 ~ 0xFFFF FFFF 이렇게 되있습니다.
C프로그램이 int 형 변수를 선언하면 소스코드로 int var1; 이렇게 쓰고 실제 프로그램 실행시 4바이트의 메모리 공간을 할당받아서 사용할 수 있습니다. 그런데 대량의 int 형 변수가 필요할 때는 일이 많아집니다. 보통 한 학급 학생들의 시험점수 예를 많이 드는데 30명이 있는 반에 수학시험 점수를 프로그램에서 사용한다고 가정해봅니다. int 를 사용하면 변수를 30개 만들어야 합니다. 코드가 30개 줄이나 될 것이고 변수를 선언하는 명령도 30회가 실행됩니다.
반면 배열의 경우 int studentScore[30]; 같이 선언하면 코드도 한줄 명령도 한줄로 처리가 됩니다. 한 학급이 아니라 한 학년, 학교전체로 확장해도 코드는 한줄만 필요합니다. 개별 변수를 사용하는 것보다 효율성이 매우 좋습니다.
배열의 구조
배열의 구조는 간단합니다.
- 요소 (element) : 요소는 배열의 구성요소를 말합니다. 구성요소는 데이터 타입에 맞는 형태만 사용가능합니다. (예: 4byte int 형 배열 요소)
- 색인 (Index) : 색인은 배열의 오프셋(offset)입니다. 메모리 주소에 색인에 데이터 타입의 크기를 곱한 값을 더하면 해당 색인의 값을 바로 추출할 수 있습니다. (Mem 주소 = 색인 * 데이터 타입) n개 요소를 가진 배열의 색인은 0부터 시작해서 n-1 까지 입니다.
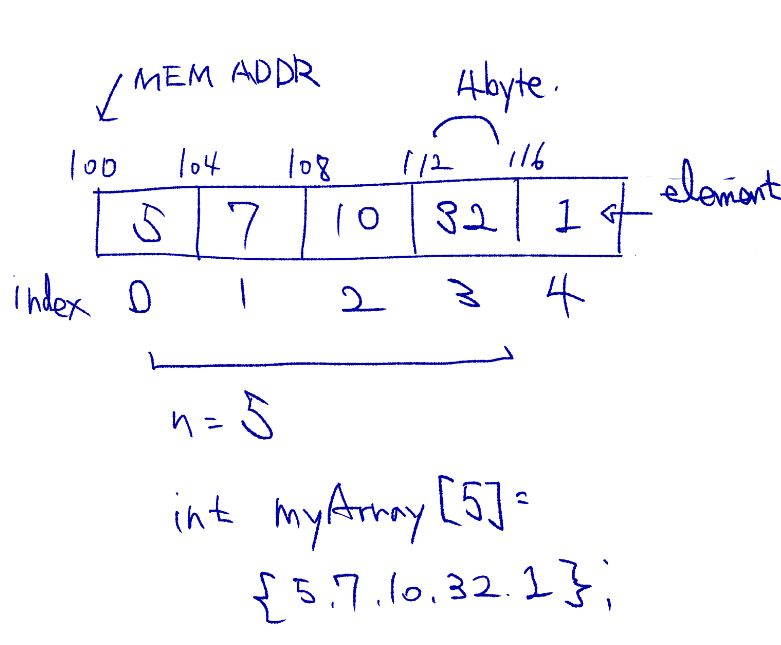
예제를 통해서 알아보겠습니다. 아래에서 int myArray[5] = {5, 7, 10, 32, 1}; 의 요소는 괄호안에 들어있는 5, 7, 10, 32, 1 입니다. 이 요소들은 실제 데이터들이죠. 색인(index)은 myArray[5]에서 [] 안에 들어있는 숫자입니다. 색인을 사용해서 요소에 접근할 수 있습니다. int 는 일반적인 PC사양에서 32bit 자료형으로 4바이트를 차지합니다. 이 배열은 myArray 라는 메모리 주소를 할당받아서 4바이트 * 5개 = 총 20바이트의 메모리 공간을 순차적으로 사용합니다.
#include <stdio.h>
int main(){
int myArray[5] = {5, 7, 10, 32, 1};
for (int i = 0; i < 5; i++)
{
printf("myArray[%d] : %d\n", i, myArray[i]);
/* code */
}
return 0;
}myArray[0] : 5 myArray[1] : 7 myArray[2] : 10 myArray[3] : 32 myArray[4] : 1
배열이란 운동장에 줄서기 처럼 순서대로 메모리를 배치받아 사용하는 방식입니다. (논리적인 하드웨어 모델에서) 배열은 1차원뿐 아니라 2차원이나 멀티 차원의 배열도 만들 수 있기 때문에 그 유용성이 큽니다.
배열에 관하여 자료구조에서 설명할 때 보통 아래와 같은 논리 메모리 모델을 가지고 이야기를 합니다. 메모리는 순서대로 나열되어 있는데 메모리를 어떻게 사용하는지는 운영체제에게 달려있고, C프로그램의 소스코드에는 변수의 이름과 메모리 주소가 연결되어 있고 데이터 타입에 따라 할당받는 메모리의 크기가 다릅니다. 물론 타입이 다르면 데이터를 입출력할 때도 차이가 있겠죠.
메모리나 데이터 타입, 변수, 배열 이런 것들이 개별적으로 동작하는게 아니라 컴퓨터 안에서 하나의 유기체로 이루어져 있습니다. 변수를 메모리에 저장하기 위해서는 데이터 타입이 필요하고 이를 연속되게 저장하고 사용할 수 있는 체계가 배열입니다.
배열이란 단어는 컴퓨터 전공자가 아니면 익숙하지 않을 수도 있습니다만, 일상 생활에서 나열이라는 말을 씁니다. 나열은 무언가 비슷한 종류의 내용을 늘어놓는 것을 말합니다. 배열도 크게 차이는 없습니다. 컴퓨터 내부의 엄격한 규칙을 따를 뿐이죠. 뒤에 가면 배열을 좀더 유연하게 사용하기 위해서 구조체라던가 클래스라던가 변형이 등장합니다만, 원조는 배열이라고 볼 수 있습니다.
객체지향프로그래밍을 배우지 않은 사람들에게는 약간 이른 이야기지만 클래스를 배열로 만든 것이 객체 배열입니다. 클래스와 인스턴스의 관계는 큰 틀에서 보면 데이터 타입과 변수의 관계와 같습니다.
객체 배열은 인스턴스를 배열처럼 묶은 것 입니다. 그러니까 컴퓨터 프로그램의 구조에는 일관성이란게 있습니다. 그래서 배열에 대해서는 처음부터 최대한 상세하게 학습하는 것이 나중을 위해서도 좋습니다.
위 예제의 배열을 이해하기 쉽게 그려보면 아래와 같습니다.
배열의 요소는 메모리에 저장되고 인덱스를 가집니다. 배열의 이름은 사실 메모리주소입니다. int myArray[5]에서 myArray 는 메모리 주소인 0x100 입니다. 여기다가 인덱스 * 4byte 를 더하면 어느 요소라도 바로 접근이 가능합니다. Access 의 시간복잡도가 빅O표시법으로 O(1)이라는 것은 한번의 절차만으로 충분하다는 뜻 입니다.
배열의 선언
배열의 선언은 변수의 선언과 같은 개념입니다. 차이라고 하면 변수는 한개의 값을 저장하기 위해서 사용하는 것 이라면 배열은 여러개의 값을 저장하기 때문에 크기를 명시해야 합니다.
char myName[20]; 여기서 char 는 데이터 타입 myName은 배열의 이름 20은 배열의 크기입니다. 배열의 크기란 offset 입니다. 각 데이터 타입의 크기와 곱하면 인덱스에 해당하는 요소의 위치를 계산할 수 있습니다.
일반화하면 type name[size]; 가 됩니다.
size가 들어가는 [ ] 괄호안에 인덱스를 넣어서 이동하는 방식인데 주의할 점은 요소 n개가 있다면 항상 n-1이 마지막 인덱스입니다. C프로그램은 여기를 넘어서는 인덱스의 메모리의 접근도 허용하기 때문에 인덱스가 넘어가지 않도록 조심합니다.
메모리를 관리하는 다른 언어중에는 index out of range 오류를 컴파일러가 차단해주지만 C는 컴파일 시 막지 않습니다. 결국 실행시간에서야 문제가 발생하는데 메모리를 잘못 건드리는 오류는 어떤 결과를 초래할지 알 수 없으며, 치명적인 경우가 많습니다.
배열의 요소 접근
배열의 요소에 접근하는 방법은 for나 while 루프를 이용합니다. 인덱스가 0부터 시작하므로 배열은 루프와 함께 사용하기가 좋습니다.
#include <stdio.h>
#define ARR_SIZE 5
int main(){
int myArray[ARR_SIZE] = {5, 7, 10, 32, 1};
for (int i = 0; i < ARR_SIZE; i++)
{
printf("%d ", myArray[i]);
/* code */
}
printf("\n");
int count=0;
while(count<ARR_SIZE)
{
printf("%d ", myArray[count]);
count++;
}
return 0;
}5 7 10 32 1 5 7 10 32 1
배열의 검색
요소에 접근하는 것은 for 루프를 돌리는 것 만큼이나 쉬운데 마찬가지로 검색도 쉽습니다. 루프를 돌면서 하나씩 if 문으로 검사를 하면 됩니다.
배열의 모든 요소를 하나씩 체크하는 것을 traverse(횡단) 라고 합니다. 모든 요소에 traverse 할 수 있으니까 당연히 각 요소의 값을 내가 검색하려는 값과 비교해볼 수 있을 겁니다.
다른 자료구조도 각각 traverse 하는 방법이 있습니다. 아래는 간단한 예제입니다.
#include <stdio.h>
#define ARR_SIZE 5
int main(){
int myArray[ARR_SIZE] = {4, 77, 34, 95, 13};
int findValue = 77;
int myIndex = 0;
int count = 0;
while(count<ARR_SIZE)
{
if(myArray[count] == findValue){
printf("*number (%d) found at myArray[%d].\n", findValue, count);
} else{
printf("- myArray[%d] : %d\n",count, myArray[count]);
}
count++;
}
return 0;
}- myArray[0] : 4 *number (77) found at myArray[1]. - myArray[2] : 34 - myArray[3] : 95 - myArray[4] : 13
for루프를 사용하거나 while 루프를 사용하거나 어느쪽이나 가능합니다. 주의해서 볼 것은 내가 찾으려는 요소가 배열에 있는지 확인할 수 있다는 것이고 인덱스로 요소에 접근하는 복잡도는 O(1)이지만 검색하는 시간은 O(N)이라는 것 입니다.
요약
설명과 예제를 통해서 배열에 대한 기초적인 이해를 해봤습니다. 이것은 논리적인 접근이지만 하드웨어를 이해하는데에는 매우 유용한 접근 방식입니다. 배열을 이해할 수 있다면 C언어의 가장 큰 난제인 포인터도 어렵지 않게 습득할 수 있을 겁니다.
C언어의 자료구조는 매우 심플합니다. 32비트 메모리 0x0000 0000 ~ 0xFFFF FFFF 4기가 바이트를 사용하는 것입니다. 여기에 1바이트 단위로 변수를 할당하고 같은 데이터 타입의 변수를 그룹으로 배열을 할당하는 것 입니다. 여러가지 자료형을 묶으면 구조체 거기다가 메소드(멤버 함수)까지 넣으면 클래스가 됩니다.
프로그래밍은 어떤 데이터에 대한 조작을 하는 것이 거의 다인데 이 자료구조를 이해하면 그 반절에 대해서 알게 되는 것 입니다.
어떻게 보면 진짜 간단한 원리이고 자료구조의 원리는 반복적으로 깊이있게 보는 것이 중요합니다. 스스로 그림을 그려가면서 하는 학습도 효과적입니다. 프로그래밍은 어려운 부분일수록 능동적인 학습이 필요합니다.
외부 참고문서
Arrays as Data Structure in C/C++ Programming – MYCPLUS